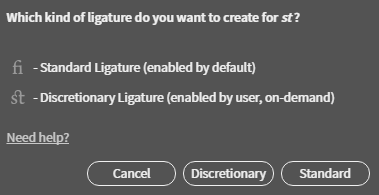
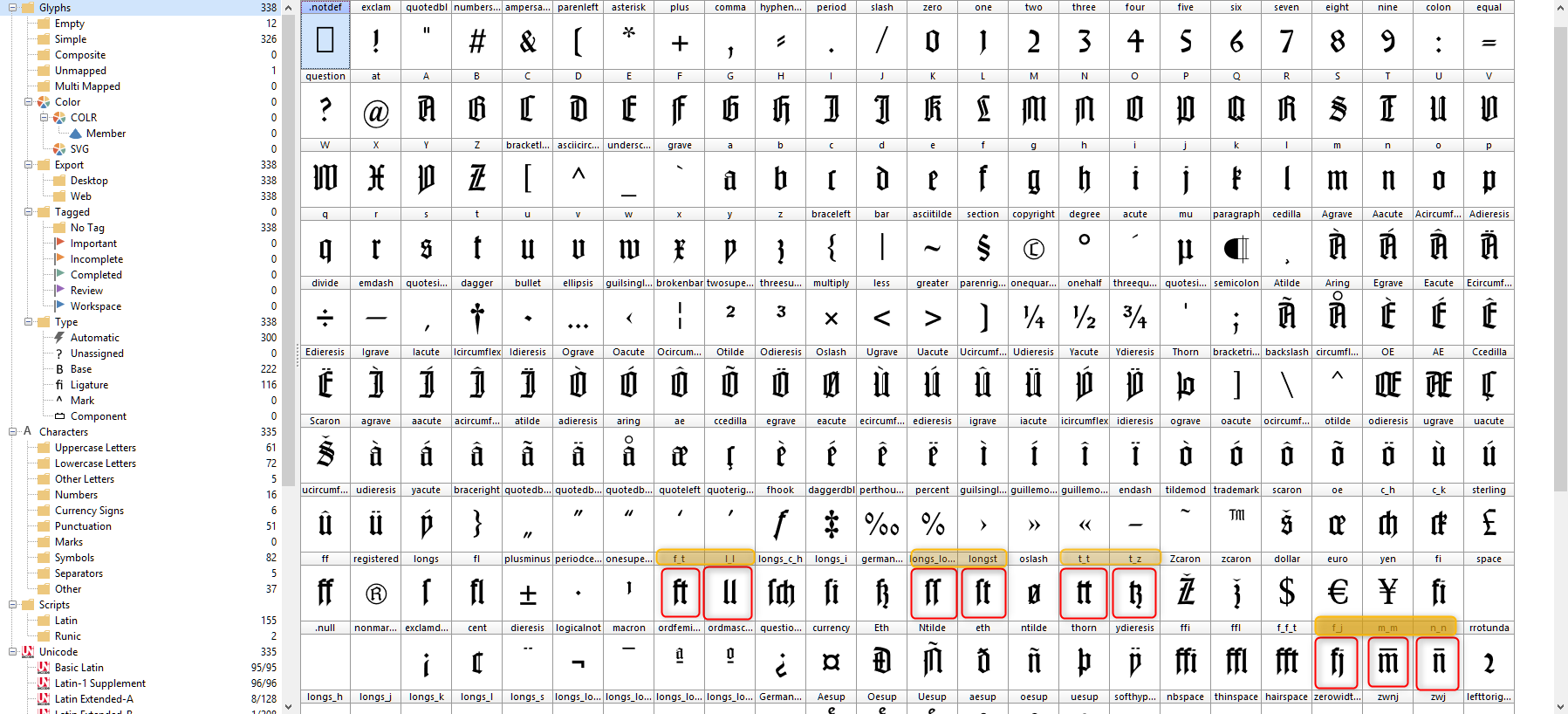
Purpose
This standard concerns the structure of digital fonts. In the first place, it is intended to facilitate the digital use of Fraktur fonts set according to the rules in the German language. For this purpose, it combines ligatures, ligature-like characters and other characters relevant to Fraktur in a list of additional characters and assigns a code position to all these characters in official and user-defined areas of the Unicode character set. These “supplementary characters” complement the basic Latin alphabet (including the six German umlaut letters) and should be applied to the type set from broken print fonts, from point type fonts, and from other Latin-based ligature fonts.
The UNZ 1 standard standardizes the production and use of type sets which are assigned additional characters in accordance with Unicode; the aim is to facilitate the handling of texts in these fonts: the texts should be easier to enter and to switch to other type sets; in addition, compatibility with spell-checking programs should be increased. The new UNZ layout no longer displaces other characters from their Unicode positions.
sorry German text:
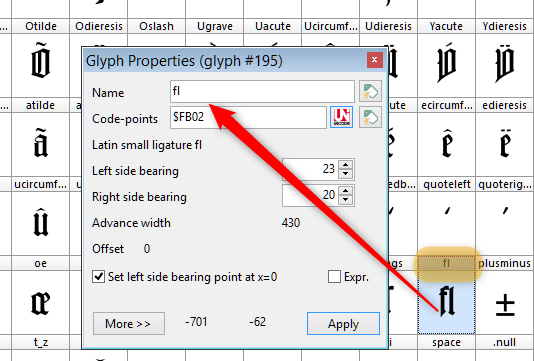
.
translation
The “Unicode-compatible standard for additional characters” (abbreviated UNZ) is a recommendation for the encoding of special characters (especially ligatures). The recommendation was developed by members of the Bund für deutsche Schrift und Sprache (BfdS) and coordinated with the “Medieval Unicode Font Initiative” (MUFI) and the “Thesaurus of Indo-European Text and Language Materials” (TITUS) project.
Background:
Typical ligatures of the classical Fraktur set (for example, ch/ck/ll/tt) have no official equivalent in Unicode. Typographic ligatures (for example fi and fl) were included in Unicode only for compatibility with existing character encodings. In addition, before Unicode was established, character sets of the Latin writing system were mostly 8-bit (256 characters) and thus rarely offered space for additional characters. This meant that providers of broken fonts had to achieve ligatures or, for example, the distinction between s and ſ through non-standardized character assignments. For example, the long s can be placed on the s key, while the round s can be placed on the plus sign position. The font user can then easily reach both characters via any conventional keyboard, but the texts are not cleanly encoded and thus not interchangeable across fonts and systems and generally difficult to process technically (search engine indexing/automatic hyphenation, etc.). The UNZ assignment should therefore create a corresponding standard for providers of broken fonts that eliminates these historically grown problems.
Advantages:
The UNZ markup creates a uniform standard for all suppliers of broken fonts and can thus avoid that the fonts (after sufficient establishment of the UNZ markup) behave differently from manufacturer to manufacturer.
UNZ assignment avoids the incorrect assignments of officially encoded Unicode digits.
UNZ encoding does not require smart font technologies to force or suppress the desired ligatures or to replace characters with historical alternate characters.
UNZ encoding is more stable in a technical sense than OpenType-based glyph substitutions, because typographic typesetting conventions are captured directly at the encoding level via UNZ encoding and are not dependent on a particular OpenType font.
Criticism: (short summary of corresponding Typografie.info discussions)
The UNZ assignment contradicts the principle of Unicode to encode only sense-bearing characters and no typographic variants. For the technical encoding of ligatures, the Unicode system has the linking inhibitor and the invisible linking character. This allows ligatures to be specified or suppressed completely independently of special fonts at the encoding level.
The UNZ assignment relies on Unicode values from the private use area (PUA). This makes UNZ-encoded texts permanently incompatible with conventional texts created with official Unicode values. “B u c h” and “B u ch” thus become different words and can no longer be processed as meaning the same by common text processing software (including search engines). Since the PUA area is by definition unstandardized, this situation will not change in the medium to long term. UNZ-encoded texts will therefore continue to be displayable exclusively with the UNZ special fonts, and their contents will be incompatible with conventional texts in the corresponding languages.
The designation as “standard” has been criticized, as this term in general usage for technical recommendations suggests a successful standardization process at a recognized standardization institute (e.g. DIN/ISO etc.). However, UNZ occupancy is merely a private recommendation developed by members of the association.